본 연구실에서는 데이터 처리 속도 향상과 신뢰성 증진을 위해, 단일 시스템과 분산시스템의 여러 소프트웨어 계층에서 연구를 수행 중이다. 단일 시스템의 입출력 성능을 높이기 위해 스토리지 스택의 최적화를 수행하고, 분산 시스템의 효과적인 리소스 스케줄링 통하여 대규모 데이터 처리 프레임웍의 성능을 높인다. 또한 다양한 계층에 보호 메커니즘을 적용하여, 데이터나 계산 결과의 손실을 줄임으로써 전체 시스템의 안정성을 높이는 연구가 진행 중이다.
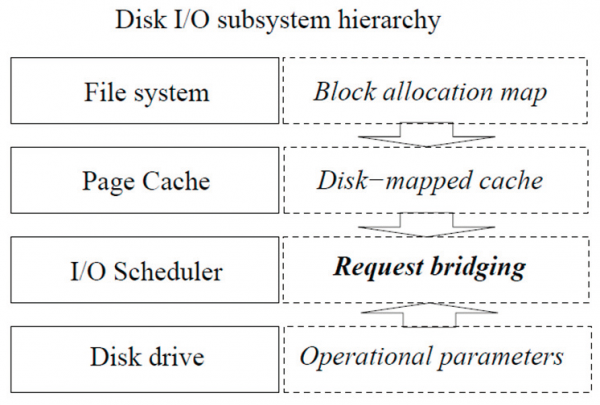
운영체제 소프트웨어 스택과 스토리지 디바이스 간의 정보 차이 메우기
최근 입출력 성능이 발달된 스토리지 디바이스들이 등장하고 있으나, 이들이 기존 운영체제에 결합됨으로써 발생할 수 있는 문제들에 대해서 분석되지 않은 경우가 많다. 본 연구에서는 새로운 스토리지 디바이스의 특성을 운영체제 소프트웨어 스택 디자인에 반영하여, 최상의 성능을 보일 수 있도록 파일시스템, 입출력 스케줄러, 디바이스 드라이버 등 다양한 계층에 최적화를 수행하고 있다.
분산 데이터 처리 프레임웍에서 중복되는 계산이나 데이터 제거하기
하둡과 같은 맵리듀스 프레임웍에서 발생하는 워크로드를 분석해보면, 계산과 데이터 측면에서 많은 중복이 발견됨을 확인할 수 있다. 계산 중복은 전체 데이터 처리 시간을 길게 만들고, 데이터 중복은 저장소 낭비로 이어진다. 따라서 계산과 데이터의 중복을 최소화하여, 데이터 처리 시간 및 사용 공간을 크게 절약함으로써 고성능, 저전력 등의 목적을 성취할 수 있다.
데이터 손실을 방지할 수 있는 결함 내성 소프트웨어 디자인 및 구현하기
결함주입법을 통해 소프트웨어 스택의 다양한 계층을 테스트해본 결과, 매우 널리 오랫동안 사용되고 있는 소프트웨어 조차도 결함에 취약하여, 치명적인 데이터 손실을 일으킨다는 사실이 최근 확인되었다. 데이터 신뢰성의 증진은 시스템 성능의 저하로 이루어질 수 있기 때문에, 두 목적간의 균형을 유지하는 것이 매우 중요하다. 성능 저하를 최소화하면서 데이터 신뢰성을 높일 수 있는 연구를 다각도에서 진행 중이다.